Mapping occupations from ESCO to job offers
Matching ESCO Occupations to Job Offers: A Mapping Guide
Introduction
Currently, the ESCO database consists of 3008 occupations. They are organized in hierarchical form. Each term has a title, alternative titles, a short description, and optional and essential skills. Records are divided into 10 groups: Armed forces occupations; Managers, Professionals, etc.
 ESCO Database (Source: https://esco.ec.europa.eu/en/classification/occupation_main)
ESCO Database (Source: https://esco.ec.europa.eu/en/classification/occupation_main)
The ESCO database is translated into 28 languages. We can download each version from the site: ESCO or from their API.
So, we have 3008 different occupations but how can we use them with job offers? Is this database reflects current labor data? Let's find out in the following sections!
Data processing
We have prepared over 4mln job offers from polish sites from 2019-2022. In the first step, we have normalized job positions into over 100k phrases. In the next step, we have preprocessed descriptions to get only relevant information about the given job (skipping benefits, company description, RODO clauses, etc.) Finally, we have a great dataset to build the model, by which we can compare various normalized job positions to others.
1>>> data.head(3) 2 3 job_position description 40 księgowy kontrola dowód księgowy pod wzgląd formalny ra... 51 księgowy sprawdzać dokument księgowy pod wzgląd formaln... 62 inspektor ds księgowości klasyfikować i dekretować dowód finansowo księ... 7 8
We have built Doc2Vec paragraph embedding model from gensim library.
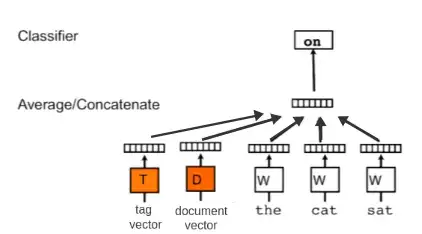 Doc2Vec model with tag vector (Source: www.shibumi-ai.com)
Doc2Vec model with tag vector (Source: www.shibumi-ai.com)
Doc2Vec model is related to Word2Vec model but can learn also numeric representations for documents or tags.
As a tag vector we have set job_position. They are an aggregated versions of all document vectors with the same job_position.
1from gensim.models.doc2vec import Doc2Vec, TaggedDocument 2 3>>> documents = [] 4>>> for i, row in d.iterrows(): 5... documents.append(TaggedDocument(row['description'].split(), [row['job_position']])) 6 7 8>>> model = Doc2Vec(documents, vector_size=50, window=5, min_count=2, workers=10, dm=0, epochs=50, hs = 1 9
Mapping ESCO database into job offers
Now, we are checking similar occupations from the ESCO database. From the ESCO database, we have found 23% of occupations in our normalized job positions.
Why only 23%? In the ESCO database, there are a lot of occupations which are supposed to be outside of job offers. For example, job offers for position ambassador occur on unique government sites, not in commercial portals. Occupation sheep breeder characterizes growers, but we don't have job offers for many self-employed people.
Let us check the names of the most similar job offers for the ESCO occupation accountant.
1model.dv.most_similar('księgowy', topn=5) 2
| Polish job name | English job name | Similarity |
|---|---|---|
| specjalista ds księgowości | accounting specialist | 0.859 |
| księgowa | accountant (F) | 0.84 |
| inspektor ds księgowości | accounting inspector | 0.825 |
| główny księgowy | accounting manager | 0.816 |
| specjalista działu finansowo-księgowego | finance and accounting specialist | 0.816 |
Ok. It looks excellent! Let us check another example for hairdresser.
| Polish job name | English job name | Similarity |
|---|---|---|
| fryzjer damsko-męski | female and male hairdresser | 0.862 |
| fryzjer męski barber | hairdresser barber | 0.795 |
| fryzjer damski | female hairdresser | 0.784 |
| fryzjer stylista | hair stylist | 0.78 |
| fryzjer męski | barber | 0.772 |
Similarities are less than in the example with the accountant, but there are still significant.
Since we have an excellent job similarity data science model, we can map our 23% ESCO occupations into commercial offers.
We apply the simple rule and map ESCO occupation when the similarity score exceeds 0.7.
This method allows us to get up to 90% of current job positions with assigned ESCO occupations.
It's nice results that can show us statistics about commercial offers related to ESCO occupations.
What about the other 10% of current job positions? We can use some sentence similarity models (like Language-agnostic BERT Sentence Embedding - LaBSE) to compare skills and descriptions from ESCO occupations with preprocessed descriptions from commercial offers. Unfortunately, the job's language style differs significantly from the ESCO style. Results should be manually corrected to use in ESCO mapping.
Conclusion
The ESCO database is still under development. It has a nice hierarchical form and versions in 28 languages. To use it, we still need some good job similarity model to compare in current job advertisements. Doc2Vec is one example of them.